Understanding the host network - SIGCOMM '24
해결하려는 문제: host network안의 contention이 end-to-end performance에 영향을 줄 수 있다.
어떻게 접근했나:
- host network를 모델링했다.
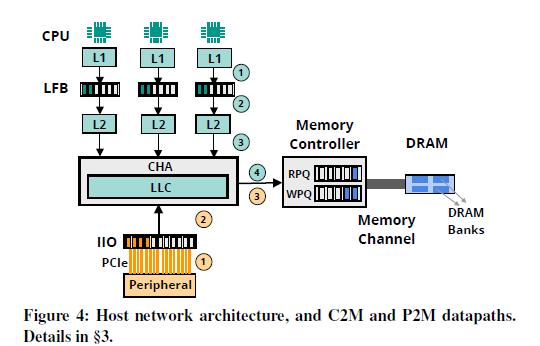
이런 식으로 간단히 Black box를 Grey box로 생각할 수 있도록. 그리고 크게 두 가지 Path가 생기는데, 하나는 Core-to-Memory, 다른 하나는 Peripheral-to-Memory 이다.
그리고 이 논문에서는 Credit-based flow control을 전제로 한다. 이 방식은 Credit을 소모해서 Request를 보내고, 그에 대한 Response를 받으면 Credit을 회복하는 방식의 Flow control이다. 당연하게도, On-flight request는 Credit의 수를 넘을 수 없을 것이고, 이를 이용해 Maximum BW도 찾아낼 수 있다. (Little's Law 쓰면 되는데 솔직히 이 당연한 결과를 Law라고 이름까지 붙일 필요가 있는지 ㅎ)
여튼간 이 논문에서 집중한 것은 저 Credit의 분배가 Contention을 만들기도 하고, Latency가 커져서 Credit을 빨리 회복시킬 수 없게 되면 그것또한 contention을 만들기도 한다.
2. 각 Path별로 Characteristic을 찾아낸다. Intel CPU를 사용하였는데 Counter 활용
1) C2M - Read : LFB - CHA - MC - DRAM
2) C2M - Write : LFB - CHA
3) P2M - Read : IIO - CHA - MC - DRAM
4) P2M - Write : IIO - CHA - MC
여기서 이 Characteristic을 검증하고 이 모델링의 근거를 만들기 위해 그래프 비교 들어감.


이 두번째 그림의 데이터들이 각 Path가 관련된 부분을 찾아낸 과정을 보여준다. 첫 그래프는 C2M-Read의 경우이고, CHA-DRAM latency가 LFB latency와 직접적으로관련이 있음을 보여줌으로써 C2M-Read에는 모든 Hop들이 포함됨을 보여준다.
두 번째 그래프는 C2M-Write에서 CHA-DRAM 이 관련이 없다는 것을 보여주는데, 빨간 빗변 그래프랑 앞서 보았던 Write latency 자체는 큰 관계가 없다는 것을 보인다.
이는 직관적으로 당연한 거긴 한데, Write 자체가 캐시에 내용 적으면 끝인 거다 보니까... 누가 필요로 하거나 캐시에서 Evict 되기 전까지는 메모리까지 갈 일이 없다.
세 번째와 네 번째 그래프는 P2M Write를 설명하기 위한 데이터인데, CHA->MC Write와 IIO Latency가 같이 움직인다는 것을 보여준다. 이로써 우리는 P2M-Write에는 C2M-Write와는 다르게 CHA->MC도 관련있음을 알 수 있다.
P2M Read는 직접적인 실험 데이터를 확보할 수는 없었는데, C2M Load와 P2M Read 를 동시에 돌린 결과 P2M-Read 는 더 많은 Credit을 갖고 있음을 확인할 수 있었다. (P2M Read는 164 Cacheline에 Saturate)
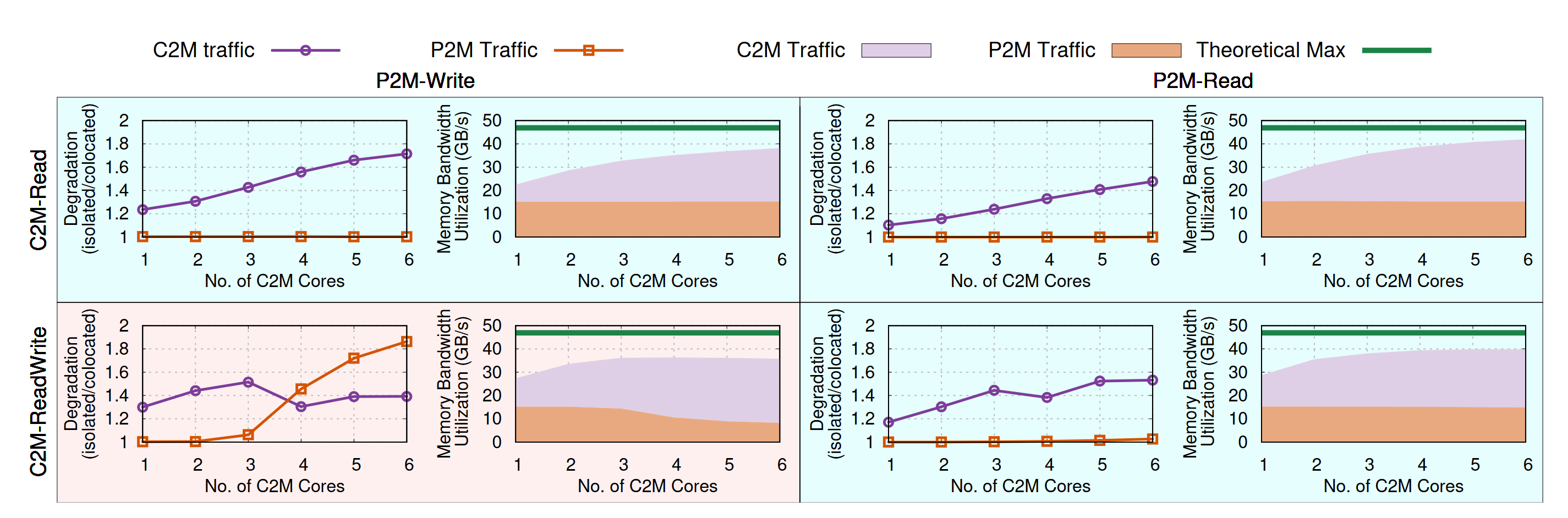
- Blue Regime 이해하기
이 파란 영역의 특징은 C2M은 성능이 저하되지만, P2M은 그렇지 않다는 것이다. 게다가 C2M이 그닥 Saturate 되지 않더라도 단순히 P2M이 존재하기만 해도 C2M의 성능은 떨어진다. 왜냐?? 바로 Domain Credit이 전부 사용되어있는 상태이기 때문에 단순히 Domain latency가 늘어나면 (Credit을 다 써서 더 issue를 못하기에) 타격을 받을 수 밖에 없는 것이다. CPU는 이 Host Network에 비해 매우매우 빠르기 때문에 Credit을 순식간에 다 소모해 버린다.
그러면 왜 Domain latency가 늘어날까?? C2M-Read와 P2M-Write를 동시에 하는 상황을 먼저 집중해보자. 겹치는 부분은 CHA-MC 부분이다. 이 논문은 이 메모리컨트롤러의 Row-Miss와 Load-imbalance 때문이라고 한다. (여기부터는 제가 RAM 구조를 잘 몰라서 확실하지 않음) 데이터가 존재하는 Row를 알아내는 시간이 필요할 때가 있다. Row-miss 되었을 때다. 그리고 이 Row의 분포는 이상적이지 않다. 모든 데이터가 골고루 분포되면 좋겠지만, 실제로는 하나의 Row에 있는 데이터를 바로 달라고 그럴수도 있을텐데 여기에 Row-miss까지 꼬이면 Latency 가 늘어나게 된다.
C2M만 있을 때는 Locality가 좋기 때문에 크게 상관이 없었다. 하지만, P2M 트래픽이 들어가면 이게 모두 꼬이게 된다. 그래서 Latency가 확 늘어나는 것이다. 이 근거로 이 논문은 메모리컨트롤러의 Queue를 보였다. P2M이 생기면 Queue가 차기 시작한다. 또한 Row miss ratio도 확 늘어나게 된다.
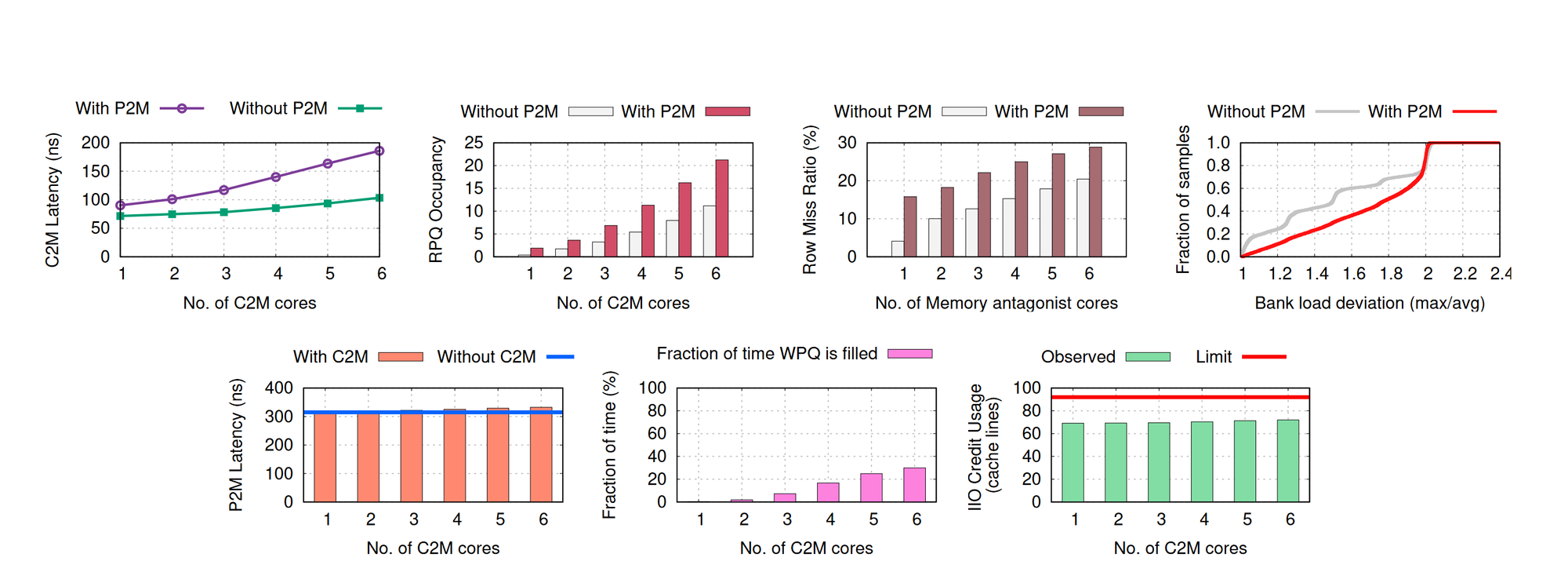
P2M-Write는 반면에 DRAM에서 대답을 기다릴 필요가 없다. 걍 큐에 던지고 오면 되는 것이고, 그래서 큐가 가득 차면 조금 느려질 뿐이다. 거기에 Credit도 BW에 비해 충분하기 때문에 대역폭도 줄지가 않는다.
- Red Regime 이해하기
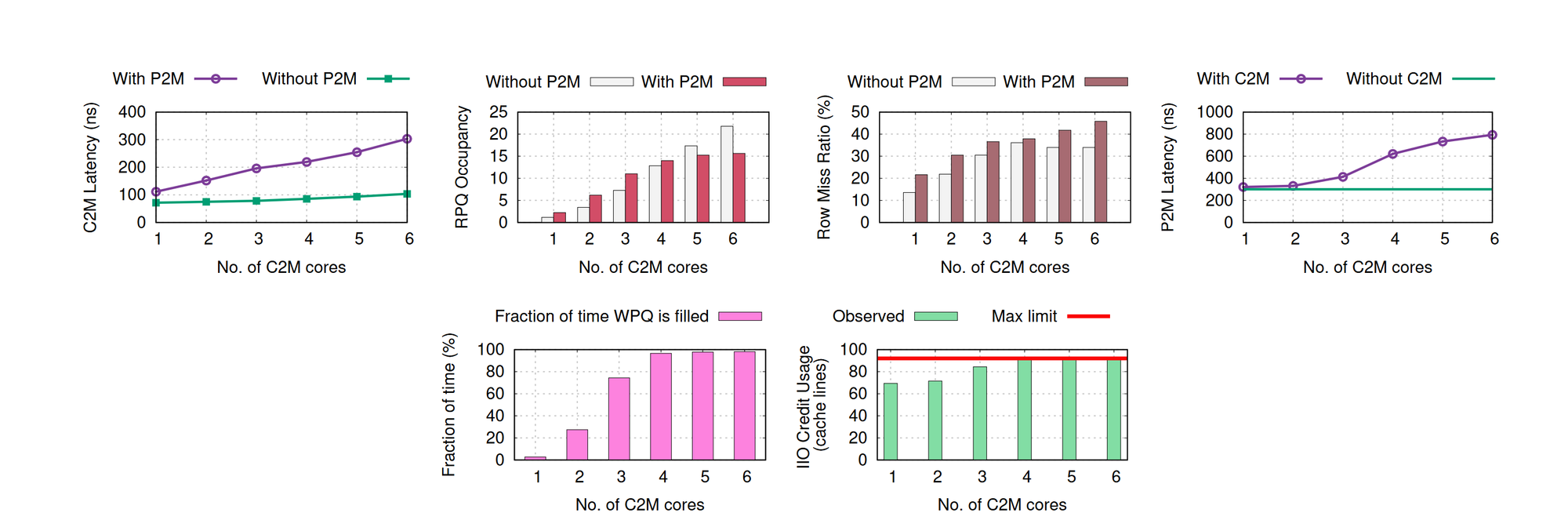
Red Regime에서 가장 핵심이 되는 정보는 Write Queue가 찬다는 점이다. 위 그림 6번째 그래프를 보면 위의 Blue Regime과는 다르게 꽉꽉 차있는 것을 볼 수 있다. 그래서 P2M-Write가 느려지는 것이다.
- 검증
이 논문은 이 모델을 수치적으로 검증했다. 개념이 크게 어려운 건 아니고 그냥 디테일적인 부분이라 여기서 설명은 생략한다.
Member discussion